
At Mindee, we are multi-cloud. Creating and maintaining dozens of APIs used millions of times per month has given us the opportunity to use the “big 3” cloud providers, in particular for their autoscaling capabilities.
In this article, we will be sharing our findings and will compare the autoscaling services of AWS, Azure, and GCP.
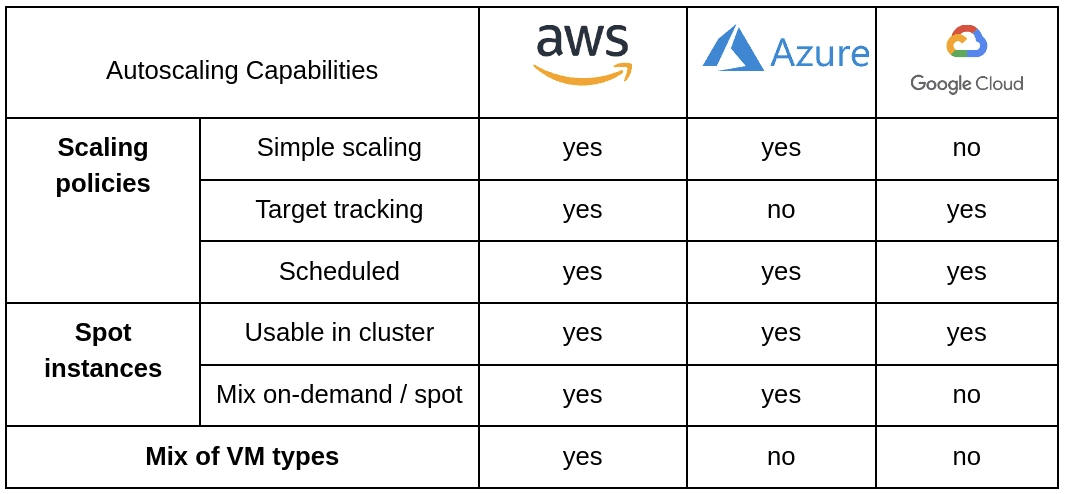
Autoscaling features
Autoscaling allows managing a pool of virtual machines and automatically adding or removing them depending on the needs.
Autoscaling clusters are called “autoscaling groups” in AWS, “virtual machine scale sets” in Azure, and “managed instance groups” in GCP.
Before comparing the differences, let’s summarize some common features of the three clouds:
- all three providers allow you to spread your cluster in multiple availability zones
- these autoscaling clusters can be associated with load-balancing services, such as AWS ALB, Azure Application Gateway, or Google Load Balancer
- the way these clusters are configured is similar: new instances are based on a virtual machine image (manually built or with tools like packer) and an initialization script provided by the user.
Finally, even though some clouds provide features for stateful clusters, we will only focus on stateless groups, which means that an instance of the group can be deleted at any time without any data loss.
Let’s now examine three key features:
- definition of autoscaling policies
- ability to use spot instances in the cluster
- possibility to use a mix of instances in the cluster
Scaling Policies
What we expect from this feature is to be able to automatically add or remove virtual machines from our autoscaling clusters, depending on various metrics such as CPU usage, the number of requests, or simply the time of the day.
Scaling policies can be separated into three groups: simple scaling, target tracking, and scheduled scaling.
Simple scaling allows you to manually define an action that should occur in response to a metric change. An example of a translation of this feature would be, “if the average CPU usage per VM reaches 40%, add 10% more VMs in the group”. You can usually trigger actions to add or remove a fixed number of instances, or a percentage.
Target tracking is a more automatic way of scaling. Instead of manually doing the changes like simple scaling, we let the cloud provider scale out or scale in to keep a certain metric at the same level. For example, “keep CPU usage to 40%” would be a good translation of the example above. Under the hood, the same behavior as simple scaling occurs; however, it is managed internally by the cloud provider and the user does not have to define it.
The last type of scaling, and the simplest one, is scheduled scaling. With it you can trigger a change in cluster size based on the time of the day, week, or year, typically using cron expressions. A common use case for this is to add more VMs during peak hours of the day, or during a certain period of the year, when we know in advance that the traffic will increase.
Now let’s see what kind of scaling is supported by each cloud.
AWS Scaling Policies
Amazon provides three types of scaling: simple scaling, target tracking scaling, and scheduled scaling.
It is interesting to note that AWS provides another type of scaling known as “step scaling”. It is basically a special kind of simple scaling, where rules can vary depending on the size of the alarm breach.
Another thing to note is that scheduled actions in AWS can change all the parameters of the autoscaling groups, i.ethe minimum, maximum, and desired capacities of the autoscaling group. The minimum and maximum capacities define the lower and upper boundaries for the autoscaling group, while the desired capacity is the actual number of instances in the group, and is also modified by other scaling policies in place.
Azure Scaling Policies
Azure Autoscale service provides only simple and scheduled scaling.
It is possible to define rules on lots of different metrics and to increase or decrease the instance count, or percentage.
In addition to that, the instance count can be changed depending on a specific schedule.
However, scheduled scaling is a bit less flexible than Amazon’s scheduled actions, because it doesn’t make it possible to change the minimum and maximum capacity in the autoscaling group.
GCP Scaling Policies
Unlike Azure, managed instance groups in Google Cloud can be scaled using target tracking, and autoscaling schedules.
Note that you have the option to choose an “autoscaling mode” between two options: “On” and “Scale-out”. The latter will only add instances to the group and prevent downsizing.
Spot Instances
This is a crucial feature in autoscaling groups because it saves costs dramatically.
Spot instances are idle instances that are available with a big discount (usually between 60 and 90% of the normal price). The downside is that these machines are not always available, and can be preempted by the cloud provider if the computing capacity is needed, at any time. Thus, these types of instances are suited for stateless and fault-tolerant workloads.
While all three cloud providers support Spot instances for single VMs, we would like to compare the following:
- Can we use spots in instance groups with autoscaling?
- Is it possible to mix On-Demand (i.e regular) instance types with Spot instances in a group?
AWS Spot Instances
AWS Spot Instances are usable within autoscaling groups, and it is possible to mix on-demand and spot instances within a group. When creating a group, you can define a “base on-demand capacity”, i.e the minimum number of on-demand instances in the group, and a percentage above base capacity.
For example, if you have 10 instances in the group and configure a base capacity of 2 and an on-demand percentage of 20%, there will be 2 + 20% of 8 = 4 on-demand instances, and the rest will be spot instances.
Azure Spot Instances
Since October 2022, Azure makes it possible to mix spot and regular instances within a Virtual Machine Scale Set. In order to do that, you have to choose a “Flexible” Scale Set. The configuration is identical to Amazon, with a base and percentage of regular instances in the group.
GCP Spot Instances
GCP allows the use of Spot (and previously “preemptible”) instances within a managed instance group, but unlike Azure and AWS, it is not yet possible to mix spot and on-demand.
When defining a managed instance group in Google Cloud, you have to define an “instance template” that contains the VM size and its type (spot or on-demand). This instance template can be changed over time, but it is not possible to use both simultaneously.
A mix of virtual machines (VM) sizes: only in AWS
Depending on your use case, you might realize that multiple instance types are suited to be part of your autoscaling cluster. For example, if the requirements for your workload are only to have 16 CPUs, you will find multiple VM types for this job: for example, AWS m5.4xlarge and c5.4xlarge, Azure F16 and D16, or Google c2-standard-16 and n2-standard-16, all fulfill this simple requirement.
For this reason, it would be interesting to leverage this power when using Spot instances in a cluster. Remember that Spot instances are not guaranteed to be available at any given time, which means that a scale-up event is not guaranteed to be completed.
AWS allows specifying more than one instance type, using mixed instances policies.
For example, you can specify both c5.4xlarge and m5.4xlarge in this configuration. The next spot instance launched will be chosen among the two based on the criteria you define: it can be the most available of the two types, or the cheapest one.
In addition to that, Amazon has implemented a “weight” strategy, permitting you to assign even more instance types and assign weights to them. For example, you can add c5.8xlarge to the cluster, with a weight of 2: meaning that 1 c5.8xlarge will be equivalent to 2 c5.4xlarge (default weight is 1).
Conclusion
While AWS is without a doubt the winner of this comparison regarding this specific service, a few things are noticeable.
Firstly, Azure is (as of today, end of 2022) making significant progress with Flexible scale sets, and introduced the possibility to mix spot and regular instances lately. Secondly, more progress is made in other areas, like the possibility to use another type of scaling known as predictive scaling, which is now supported by the three clouds.