
API DEV-First
4.8/5 (30+ reviews)
AI‑Powered receipt OCR API to improve data extraction
Mindee OCR API extracts structured receipt data that adapts to any layout and hand-written styles. Capture Merchant name, total amount, currency, taxes ... from scanned images and PDFs.
Try with a receipt
No credit card required
.svg)
.webp)
Trusted by top-tier teams worldwide

Why choose Mindee as receipt OCR API
Reliable data extraction
Flawless data extraction, no typing. Slash your receipt processing time.
Developer-friendly API
Immediate time-to-value with our SDKs & no-code tools integration.
Enterprise-grade security
Host your data where you need (EU or US) and enjoy our SOC 2 Type II certified API.
Multi-languages/formats
Our API supports any file formats (PDF, JPEG, PNG,...) , in any languages or alphabets.
Scalable implementation
Handle growing receipt volumes effortlessly, with cost-effective API
4.8/5 sur G2
(+30 reviews)
4.9/5 sur Capterra
(+10 reviews)
Deep understanding for any receipt fields you need, with modern OCR
A sample of receipt fields automatically detected
Receipt number
Receipt date
Total taxes
Tax rate
Total amount
Transaction date
Currency
Merchant name
Merchant address
Payment type
Line items description
Line items quantity
Unit price
Merchant phone number
Store number/ID
Gratuity/Tip
Server/Employee name
... and more!

.webp)
Most advanced AI OCR features getting your receipt extraction to the next level
Engineered for fintech, our receipt OCR API leverages deep learning to automate expense tracking with pinpoint accuracy, extracting line items and merchant data reliable.
.webp)
Speed up workflows by automatically splitting long scans into individual receipts. Our solution detects edges and boundaries to parse messy batches into clean, distinct expense records ready for instant data extraction.
Automate your pipeline by classifying receipts instantly. Our OCR API identifies merchant types, tax rates, and currencies, routing each slip to its proper ledger for seamless expense management.
Digitize expense slips by detecting multiple receipts on a single scan. Our OCR API crops and isolates every ticket into a standalone file, ensuring each line item is processed with total precision.

Turn your receipts into structured JSON format
Driven by neural networks, our API expertly extracts and structures retail data—totals, VAT, merchants, and line items—from any receipt into validated JSON. Engineered for any file formats, it ensures a flawless sync with your expense apps, loyalty programs, and financial databases. Scale your automation and eliminate manual entry with high-precision, machine-readable output.
API designed for global retail scale
Clean, app-ready data for your ecosystem
Robust API to ingest receipts easier
.webp)
Upload any file formats
Process PDFs, scans, and photos without templates. The API adapts to languages, currencies, and multi‑page documents automatically.

Line-item level extraction
Extract line items, key fields, and tables from any document layout—ideal for business process automation and data intelligence.
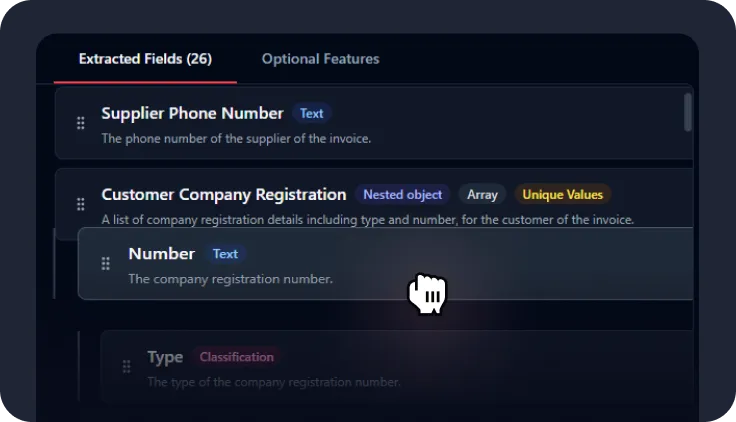
Select and map necessary fields
You can customize your data schema, to extract only fields you need and structure them on‑the‑go. Mindee API is a template-free solution.
With Mindee API, empower your expense and retail accounting teams to...
Reduce manual typing tasks
Speed up claims
Ensure merchant data purity
Fast-track repayments
.webp)

What does it mean doing receipt OCR with Mindee API ?
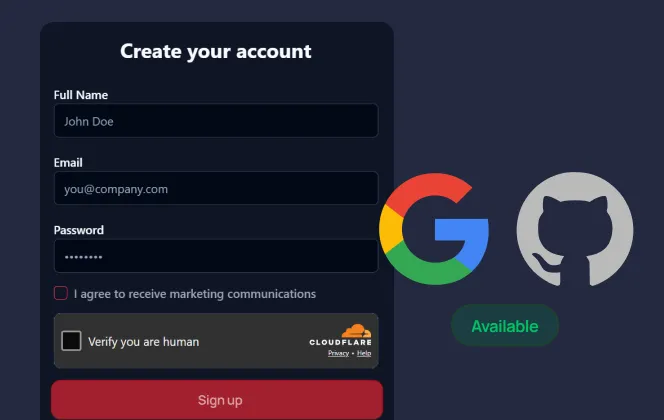
1
Sign up for free (14‑day free trial)
Sign up to try Mindee's receipt OCR API. Fast authentication with Google & Github, no credit card required.
.webp)
2
Use our pre-built receipt model or create yours
Start with our ready-to-use receipt template, or build your own from scratch to define the key fields you want to extract.
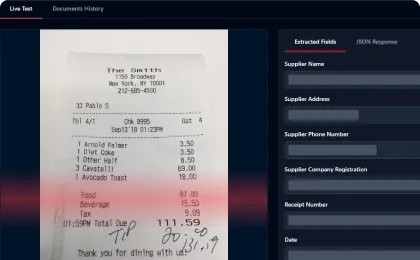
3
Live test your settings
On Mindee's app, you can live test your model set up. Update on‑the‑go with our assistant.
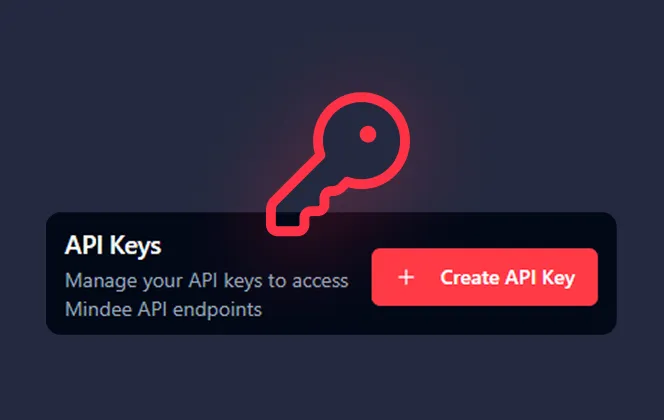
4
Setup your API integration to process at scale
Once your model performed as you want on a single document, create your API key and integrate it to your workflow.
Developers and technical profiles already used it !
Add modern AI-based Mindee OCR API to your product, in minutes.

Mindee is an integrated document processing platform backed by reliable AI technology. The service has an intuitive and user-friendly interface and provides highly accurate results extracting data from various document types, especially financial receipts and invoices, which are relatively complex and require specialized optical character recognition (OCR) services. The platform provides seamless integration with our current data processing workflows through customizable APIs, allowing for efficient data extraction and automation.

Amar A.
Mindee is a software that helps us to convert all of our physical business data like bills, invoices, warranty cards, calendar, recipts received to us into a digital documents that can be stored in our drive and can be uploaded in different type of Excel sheets so that all the updates can be maintained and a proper analytics of transactions can be kept by the financial team
Shiv K.
Mindee is a web based tool that help us in scanning and reading different type of documents like identity cards, invoices, proposal plans etc and extract all the information with its AI and then it provides all the information and data associated with these documents a structured way.
Gaurav K.
Excellent. In addition to their great product, the sales team has always been proactive on how they could help us leverage the maximum results from their product. It was like having an additional product manager on our side
Jeff B.
Mindee works reliably and delivers good performance. The OCR data is accurate, and the API is stable. It works like a charm.
Manuel B.
Mindee is a web based tool that help us in scanning and reading different type of documents like identity cards, invoices, proposal plans etc and extract all the information with its AI and then it provides all the information and data associated with these documents a structured way.
Simon

.svg)
Ready to transform your receipt OCR processing ?
Add modern AI-based receipt OCR API to your product, in minutes.
14 day free-trial
No credit card required
FAQ about Mindee's OCR API
How can I test the receipt OCR API?
The receipt OCR API is available to any user having an account on our platform and includes a 14 days free trial.To test our APIs, you only have to create an account using this link, and you'll be able to upload file in our user interface to see ID OCR in action, as well as the json output.
Does the receipt OCR work on low-quality images?
Yes, our models like the receipt models are trained on diverse real-world datasets to handle constraints such as blurriness, folds, ink stains... This ensures optimal extraction performance on documents of varying quality.
What is the receipt OCR accuracy?
Accuracy of our receipt API is generally above 95% for most fields. We compute accuracy and precision metrics every week on an evolutive dataset that includes more than 50 countries with a wide variety of receipt (formats, languages, qualities etc..). By activating some of our features, accuracy can be even closer to 100% by fine tuning your model to your use case. Feel free to try out yourself and see how it works on your data.
How complicated is it to integrate the receipt OCR API?
Mindee's API follows HTTP standards in order to allow any developer to integrate the receipt OCR API into their applications easily.We also offer a set of client libraries in all the main back-end languages and no-code tools. You can check out our API documentation for more details.
Is Mindee's receipt OCR API free to use?
We provide a 14 days free trial so you can fully test our Receipt OCR API — no credit card required. After this, we offer different pricing tiers depending of the volume of pages processed and the features you might need. See the pricing page for more information
Can it handle receipts from any country or in different languages?
Yes, our receipt OCR API is able to extract data from multiple languages in any alphabet from all countries.
How does the receipt reader API work?
Leveraging AI and deep learning, our API quickly interprets receipt images, turning them into structured data for easy use within your applications.
