.svg)


Table of Contents
Multiprocessing queues in Python allow multiple processes to safely exchange objects with each other. However, these queues can become slow when large objects are being shared between processes. There are a few reasons why this may be the case:
- Pickling and unpickling: Objects placed on multiprocessing queues are pickled, transferred over the queue, and then unpickled. The pickling and unpickling steps add overhead, and for large objects this overhead can be significant. This is because large objects require more data to be pickled and transferred, and the unpickling step requires reconstructing the entire object.
- GIL limitations: The Global Interpreter Lock (GIL) prevents multiple native threads from executing Python byte-codes at once. This lock is necessary mainly because Python’s memory management is not thread-safe. Since multiprocessing queues use locks to safely transfer objects between processes, the GIL can limit performance when transferring large objects that require acquiring the lock for long periods of time.
- Memory copying: Multiprocessing queues create copies of objects when they are transferred between processes. For large objects, creating copies can be very expensive in terms of time and memory.
To improve performance, it is best to avoid sharing large objects over multiprocessing queues when possible.
If necessary, one approach is to share memory objects using the multiprocessing.sharedctypes module instead of pickling, which avoids the overhead of pickling and unpickling.
Multiprocessing experiment highlighting the problem
Here is the experiment in Python. The only difference between our two experiments is the size of the objects shared through the queue. All of the intensive computation (the matrix multiplication) is exactly the same regardless of what we put in the queue.
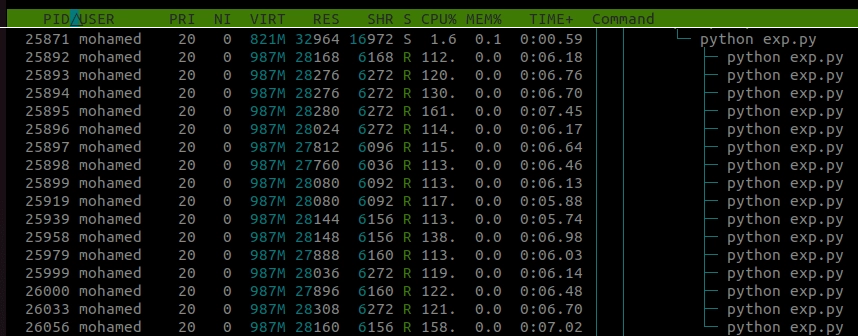
This runs on my computer in approximately 7 seconds. As we can see the status of each sub-process is R meaning that it is running.
Let’s put a heavy numpy array in the queue instead.
Replace the line where we put a 1 in the queue by :
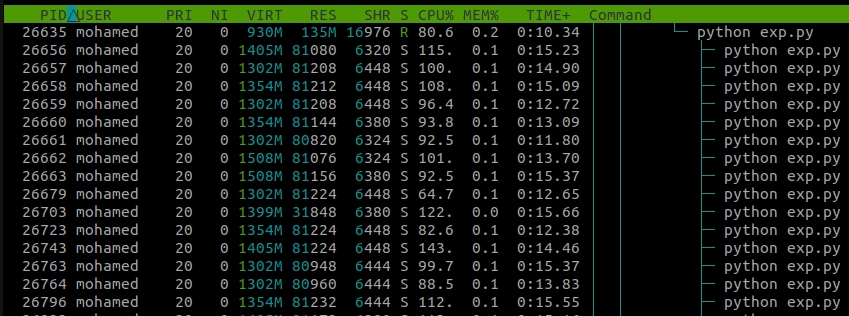
This runs on my computer in approximately 145 seconds. It is more than 20x slower even if the computations are exactly the same. As we can see the status of each sub-process is S meaning that it is sleeping.
Writing directly to the hard drive to communicate between processes instead of using multiprocessing Queues in Python has some pros and cons:
Pros:
- Avoiding the pickling and unpickling overhead for large objects. Writing to disk avoids serializing the objects.
- Avoiding the memory copying that occurs with Queues. Objects are written once to disk instead of being copied into the Queue.
- Potentially faster I/O performance by writing sequentially to disk instead of appending to a Queue.
Cons:
- Synchronization between processes must be manually handled. Queues provide a thread-safe implementation for exchanging objects between processes.
- Error handling is more complex. The Queue implementation handles errors that may occur during object transfers. This logic would need to be reimplemented.
- Objects on disk are not accessible from Python and must be loaded before use. Queue objects remain in memory.
About
.svg)