
.svg)



Table of Contents
As a developer, you've probably encountered the challenge of string matching. Whether you're building a spell checker, fuzzy search engine, or trying to compare strings in your database, exact matches aren't always enough—especially when dealing with typos or OCR-generated text.
In this article, we’ll explore practical methods for approximate string matching using Python. We’ll cover:
- Three popular metrics for string similarity: Jaccard distance, Longest Common Substring, and Levenshtein distance.
- How to leverage Python libraries like difflib, fuzzywuzzy, and regex.
- Code examples you can adapt to your own language of choice.
Metrics for Effective String Comparison
String matching often depends on comparing how similar two strings are, even when they're not exactly alike.
Choosing the right similarity metric depends on your context: do you care about speed, accuracy, or tolerance to typos?
There are plenty of ways for measuring string similarity but we will be discussing these below:
- The Jaccard distance, great for quick, set-based comparison.
- The longest common substring percentage, useful when character order matters.
- The Levenshtein similarity (that can also be used to calculate confidence score), best for typo-tolerance and edit tracking.

The choice of metric for string comparison largely depends on the specific requirements of your application.
For instance, if you are dealing with large datasets where performance is critical, simpler methods like Jaccard distance may be preferred due to their speed.
However, if accuracy is important, especially in cases where character order and typographical errors are significant, more sophisticated approaches like Levenshtein similarity or the longest common substring percentage may be more appropriate.
Understanding the strengths and weaknesses of each method will help you select the most suitable one for your string matching needs!
The Jaccard Distance
One of the simplest methods for measuring similarity between two sets of elements is to use the Jaccard distance.
Essentially, it calculates the ratio of the count of unique characters that appear in both strings to the total count of unique characters that are found in either of the two strings. This ratio provides a clear numerical representation of how similar or different the two strings are based on their unique character contributions.
Here is the implementation of the Jaccard distance in Python:
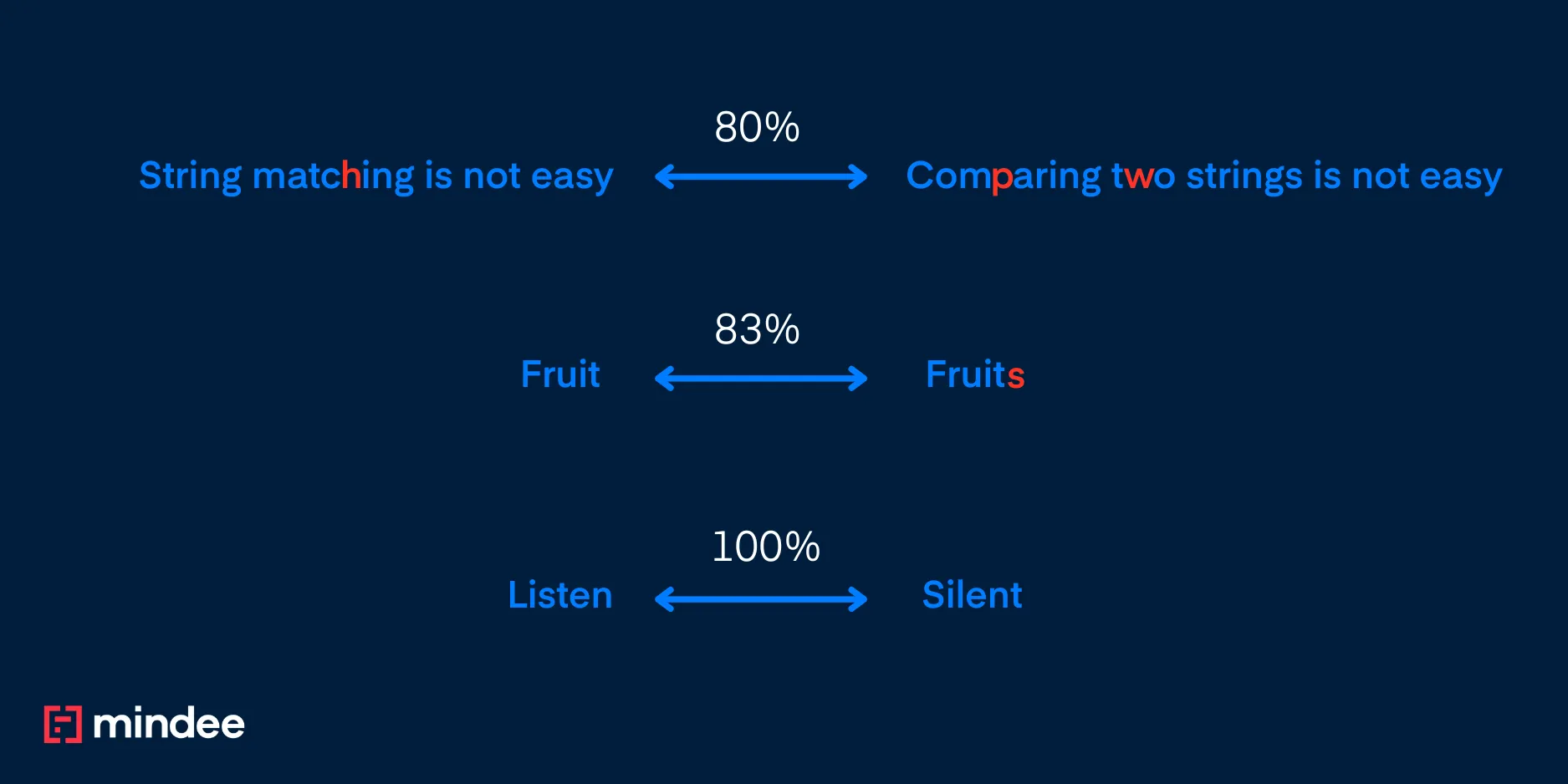
For example, the Jaccard similarity between “fruit” and “fruits” is 5/6.
How effective is this metric, you might ask? It is actually fairly simple and easy to implement, which makes it quite appealing for various applications. However, one significant limitation is that it does not consider the order in which the characters appear.
For example, the Jaccard distance between SILENT and LISTEN is …… 1 – 6/6 = 0. So we need something more robust.
The Longest Common Sub-string Percentage
The longest common substring refers to the longest sequence of characters that can be found in both of the given strings.
To visualize this concept, consider two strings, which could be sequences of letters or numbers, and determine the segment of characters that they share in common, and is the longest in length. This idea leads us to a way to measure how similar the two strings are by calculating the ratio.
This ratio is determined by dividing the length of that longest common substring by the shorter of the two strings' lengths. This approach gives us insight into how closely related the strings are to each other based on the characters they contain.

So in the examples above:
- “Fruit” and “Fruits” gives 100% score as the full word “Fruit” is the longest common substring and
- “Listen” and “Silent” gives 1/3 , as two characters (”en”) out of six are common
Depending on your use case, you can also compute the ratio using the maximum length from both strings:
- Using minimum length: A score of 100% means that one of the two strings is completely included in the other.
- Using maximum length: A score of 100% is possible only when the two strings are exactly the same.
Here is a python implementation of this method using difflib:
However, what happens if I want to compare “goodbye” and “goozbye”? Well, the longest common substring is “goo” so the similarity would be 3/7 which is very low given that only one character differs.
Levenshtein Similarity
The Levenshtein distance is a concept used to measure how different two strings are from each other. Specifically, it calculates the minimum number of changes that must be made to one string in order to transform it into another string.
These changes can include actions such as inserting a character, deleting a character, or substituting one character for another.
By counting these changes, the Levenshtein distance provides a numerical value that represents the level of dissimilarity between the two strings being compared.
The Levenshtein distance is actually a specific instance of a broader category known as EDIT distance.
While the Levenshtein distance assigns a uniform weight of 1 to each type of modification—meaning that every insertion, deletion, or substitution counts the same—EDIT distance in general allows for different weights to be assigned to different types of modifications.
This means that in the case of EDIT distance, you can prioritize some changes as being more significant than others, allowing for a more nuanced comparison between strings.
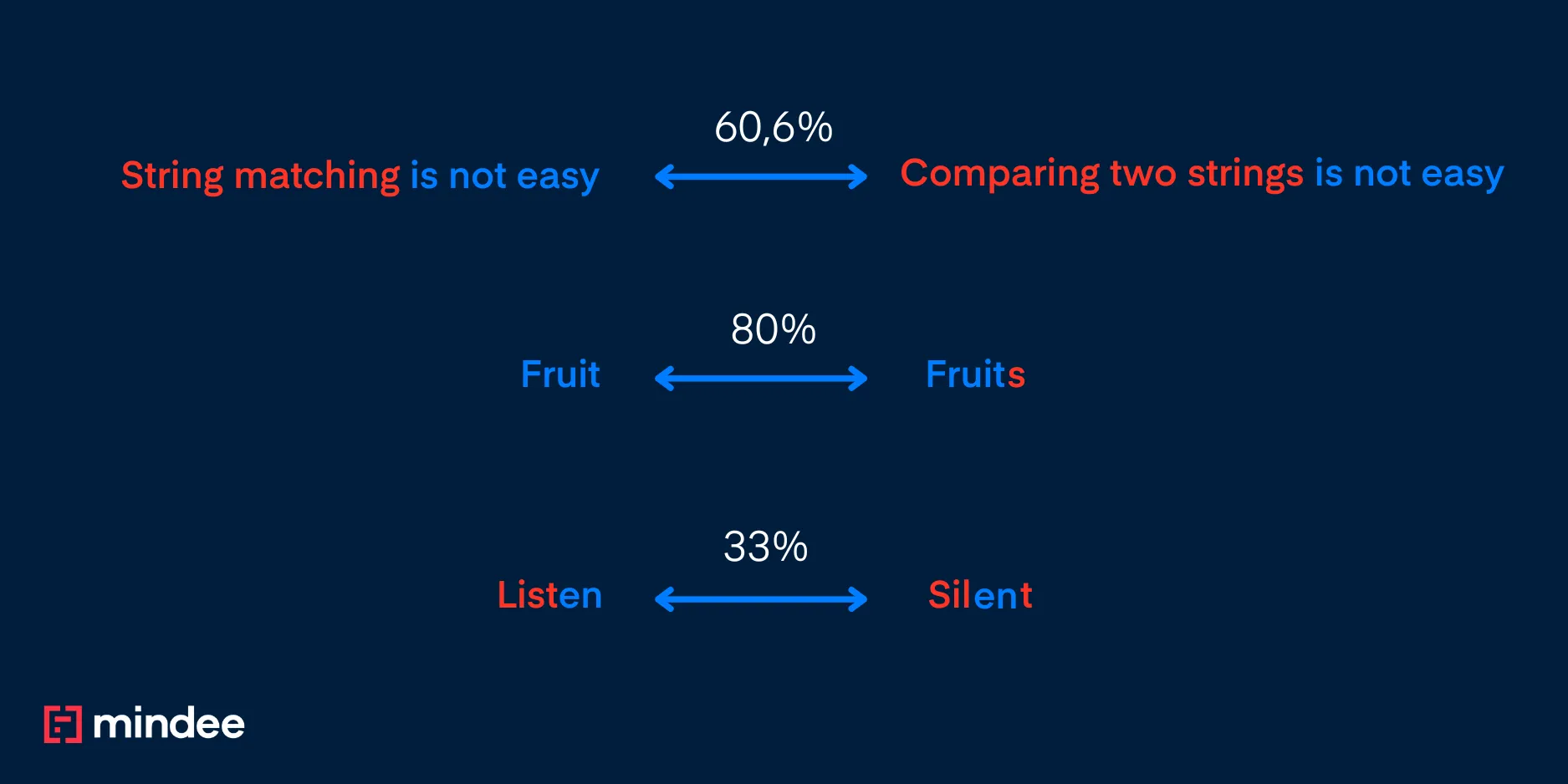
So in the examples above:
- “Fruit” and “Fruits” gives an 80% score as one error is introduced by ‘s’ out of five characters for the smallest word, hence 1-(1/5) being 80%
- “Listen” and “Silent” gives 33% as the minimal number of operations to make them match is 4 with two replacement needed, one insertion and one deletion, hence 1-(4/6) being 33%
The EDIT distance gives more flexibility because it’s possible to fine-tune the weights in order to fit your problem better.
A modification can be of 3 types:
- Insert: Add an extra character
- Delete: Delete a character
- Replace: Replace a character
NB: Sometimes, the Replace modification is not used and is considered as a deletion plus an insertion. You can also find some definitions including the Transposition modification.
To get a comparison score from the Levenshtein distance as on the other methods, we can divide the distance by either the length of the shortest string or the longest string.
Here is an implementation of a comparison score using Levenshtein distance:
How to Search Allowing Mistakes Using Regular Expressions?
The package regex in Python allows searching using regular expressions that allow fast search in text data. This package has a powerful feature that allows partial regex matching. We will introduce this feature and give a taste of its power in the following paragraph.
Approximate Matching with Regex
Regexes are used to define a search pattern and allow to find matches inside strings. The use of approximate matching is possible using packages like regex in python: it can allow the search for a pattern with some acceptable errors.
The regex library's approximate matching capabilities are particularly useful in scenarios where data may be imperfect or contain errors, such as in OCR outputs.
By allowing for a certain degree of flexibility in the search patterns, developers can effectively retrieve relevant information even when the input strings are not exact matches. This feature is invaluable in applications like text analysis, data cleaning, and natural language processing, where the ability to account for variations and mistakes can significantly enhance the accuracy and reliability of results.
You may be interested in searching keywords in a scanned document having OCR errors.
In fact, OCR errors can show some recurring patterns (like the following: “w” → (“vv” or “v”), “O” → “0” , “y” → “v”), hence by allowing some maximum number of errors or by specifying the type of errors allowed (insertion, deletion, substitution) we can find those keywords, as in the examples below:
The identifier for allowing general errors is : {e} , by doing this we are not specifying how many errors are tolerated, hence to put an upper limit to the number of errors we will use the sign “≤”, for example, an upper limit of two errors we will use {e≤=2}.
Moreover, we can specify the character introducing the error, which can be introduced by substitution/insertion forming the error, by using this identifier {e<=2:[v]}.
The upper limit for the number of errors can be more specified, as we can specify it by error type, as in the last example above: we wanted the sum of the number of substitutions and number of insertions not to exceed 2, resulting in this identifier {1s+1i<=2:[v]}.
You can also take a look at our article on how to build AI products!
Conclusion
As we have observed, there are numerous techniques available for conducting approximate search and matching in various contexts. These techniques can vary widely in complexity:
On one end of the spectrum, we have simpler methods like Jaccard distance, which provides a straightforward way to measure similarity between sets.
On the other end, we encounter more sophisticated approaches, such as Levenshtein similarity, which calculates the minimum number of single-character edits required to change one string into another.
Additionally, these methods can be effectively utilized in conjunction with regular expressions through the Python regex library. This integration enables users to perform fast and efficient searches within textual data, making it easier to locate patterns and match strings according to specific criteria.
About
.svg)

.webp)
.webp)
.webp)