.svg)


Table of Contents
Imagine relying on an OCR solution that feeds your system with the wrong data: invoice totals misread, customer names incoherent, or product codes misinterpreted. Sounds frustrating, right? That’s why OCR accuracy isn’t just a feature—it’s the pillar of any document automation solution!
Whether you’re building an app, streamlining operations, or chasing peak efficiency, understanding OCR accuracy is critical to choose the right provider.
In this guide, we’ll break down what OCR accuracy truly means, why it’s so crucial for your business, and how to evaluate it effectively. We’ll explore essential metrics like Exact Match Rates, Word Error Rate (WER), and Character Error Rate (CER) to help you measure accuracy.
But accuracy alone doesn’t tell the whole story, so we’ll also dive into broader performance indicators, including F1 Score and Automation Rate, to ensure your OCR API delivers where it counts.
And since we believe in walking the talk, we’ll wrap up with a case study showcasing how Mindee computes OCR accuracy in a real-world scenario. By the end, you’ll have all the insights you need to pick the OCR solution that’s tailor-made for your business.
Before digging more into it, know that you can also download Mindee's free benchmark tool!
Ready to decode the best OCR API for your needs? Let’s get started!
What is OCR accuracy?
Definition of OCR accuracy
OCR accuracy refers to how exact an OCR (Optical Character Recognition) system can be while transcribing text from an image or scanned document into a machine-readable format.
It is a quantitative measure of how closely the extracted data matches the ground truth (the expected value written in the document), typically expressed as a percentage or through metrics like Exact Match Rate, Word Error Rate (WER), or Character Error Rate (CER).
For businesses, achieving high OCR accuracy is essential for minimizing downstream errors, ensuring data reliability, and reducing the manual effort required for validation and correction.
Why is accuracy important to choose your OCR solution?
Whether processing invoices, legal contracts, receipts, or IDs, accuracy directly impacts efficiency, cost, and decision-making.
A solution with poor accuracy leads to frequent errors, sometimes difficult to spot, which can mean long manual intervention, wasted resources, and potential data quality issues.
On the contrary, a highly accurate OCR system delivers:
- Fewer errors and manual corrections: high accuracy minimizes error rates, which in turn reduces the manual labor needed to validate and correct extracted data which is particularly crucial for businesses managing high-volume document processing.
- Higher quality tasks: users will be able to focus on high added-value tasks, since the few documents to review will be the trickiest ones.
- Better automation rates: high accuracy drives greater trust in fully automated workflows. When your OCR is consistently accurate, you can confidently integrate it into processes without the need for human oversight.
- Faster processes since less manual interaction.
- Enhanced customer and user experiences : for customer-facing applications (e.g., mobile apps that scan IDs or receipts), accuracy is synonymous with user satisfaction. Misinterpretations can lead to poor experiences, undermining trust in your product.
- Compliance and risk diminution: in industries like finance, healthcare, and legal, where precision is non-negotiable, inaccuracies can lead to compliance issues or costly mistakes.
- Scalability: reliable accuracy ensures that as your document processing volumes grow, your operations remain scalable without compromising quality or speed.
When evaluating OCR solutions' pricing, accuracy is the baseline but the true value comes from understanding how it integrates with broader performance metrics like speed, reliability, and adaptability to your unique business use case.
The best metrics to evaluate an OCR accuracy
Exact match rate per field (EMR)
What is EMR?
The Exact Match Rate (EMR) is a critical metric for evaluating OCR accuracy, particularly for use cases where structured data extraction is required.
It measures the percentage of fields in a document where the OCR output matches the ground truth data exactly, without any discrepancies.
This metric is especially useful when extracting data from standardized forms such as invoices, receipts, or IDs, where each field (e.g., "Total Amount," "Invoice Number," or "Date") needs to be correct for the document to be fully usable.
For each field in a dataset, the OCR system's extracted value is compared against the true value (ground truth). The EMR is then calculated as:
For example, if an OCR system processes 1,000 fields and correctly extracts 950 of them, the EMR would be 95%.
When to prioritize EMR?
Exact Match Rate per Field should be a top consideration when evaluating OCR solutions if your business relies on structured documents and the complete accuracy of individual fields is critical like financial reporting, tax compliance or logistics.
By focusing on this metric, you ensure your system consistently delivers reliable outputs that minimize manual correction and maintain data integrity.
The WER (Word Error Rate)
What is WER?
Word Error Rate (WER) is a widely used metric for evaluating OCR accuracy, especially in scenarios where the focus is on text recognition rather than structured data extraction.
It measures how many words in the OCR output differ from the ground truth, accounting for substitutions, deletions, and insertions.
WER is expressed as a percentage, with lower values indicating higher accuracy. It is particularly useful in applications such as document digitization, transcription of handwritten text, or multi-language text recognition.
The formula for WER is as follows:
Here:
S: Number of substitutions (wrong words replaced with incorrect ones).
D: Number of deletions (words missed by the OCR system).
I: Number of insertions (extra words incorrectly added).
N: Total number of words in the ground truth.
For example, if the ground truth text has 100 words and the OCR system introduces 5 substitutions, 3 deletions, and 2 insertions, the WER would be:
When to prioritize WER?
WER is most valuable when assessing the OCR performance for free-text recognition, such as archiving books and manuscripts, automating transcription of meeting notes or legal documents or digitizing historical records or text-heavy scanned files.
By combining WER with other metrics like Exact Match Rate or Character Error Rate, you can achieve a more comprehensive evaluation of OCR performance tailored to your specific use case.
The CER (Character Error Rate)
What is CER?
Character Error Rate (CER) is another key metric for evaluating OCR accuracy, focusing on character-level precision rather than words or fields.
It measures how many characters in the OCR output differ from the ground truth, accounting for substitutions, deletions, and insertions, relative to the total number of characters in the ground truth.
CER is particularly useful in scenarios where word boundaries may not exist (e.g., numerical data, alphanumeric codes) or where exact character recognition is critical, such as serial numbers, product codes, or financial data.
The formula for CER is:
Where:
- S: Number of character substitutions (wrong characters replacing correct ones).
- D: Number of character deletions (characters missed by the OCR system).
- I: Number of character insertions (extra characters incorrectly added).
- N: Total number of characters in the ground truth.
For example, if the ground truth text contains 1,000 characters, and the OCR system introduces 10 substitutions, 5 deletions, and 3 insertions, the CER would be:
When to prioritize CER?
CER is most valuable when precision at the character level is crucial, such as financial transactions, logistics and supply chain or technical documentation.
When combined with other metrics like Word Error Rate (WER) or Exact Match Rate (EMR), CER provides a more comprehensive evaluation of OCR performance, enabling you to make informed decisions tailored to your specific use case.
The Levenshtein Distance
What is the Levenshtein Distance?
Now that we've discussed the error rate, let's take a closer look at the metric behind it.
The Levenshtein Distance, also known as the Edit Distance, is a metric used to measure the difference between two strings.
It calculates the minimum number of single-character operations (insertions, deletions, and substitutions) required to transform one string into another.
In OCR evaluation, Levenshtein Distance is used to quantify how closely the OCR output matches the ground truth at the character level, providing insights into the system’s accuracy in capturing text.
Unlike metrics that measure relative accuracy (e.g., CER or WER), Levenshtein Distance provides an absolute measure of error.
The Levenshtein Distance between two strings is determined by constructing a matrix where:
- The rows represent the characters of one string.
- The columns represent the characters of the other string.
- The matrix is populated by calculating the cost of aligning each character, based on the minimum cost of insertions, deletions, or substitutions required at each step.
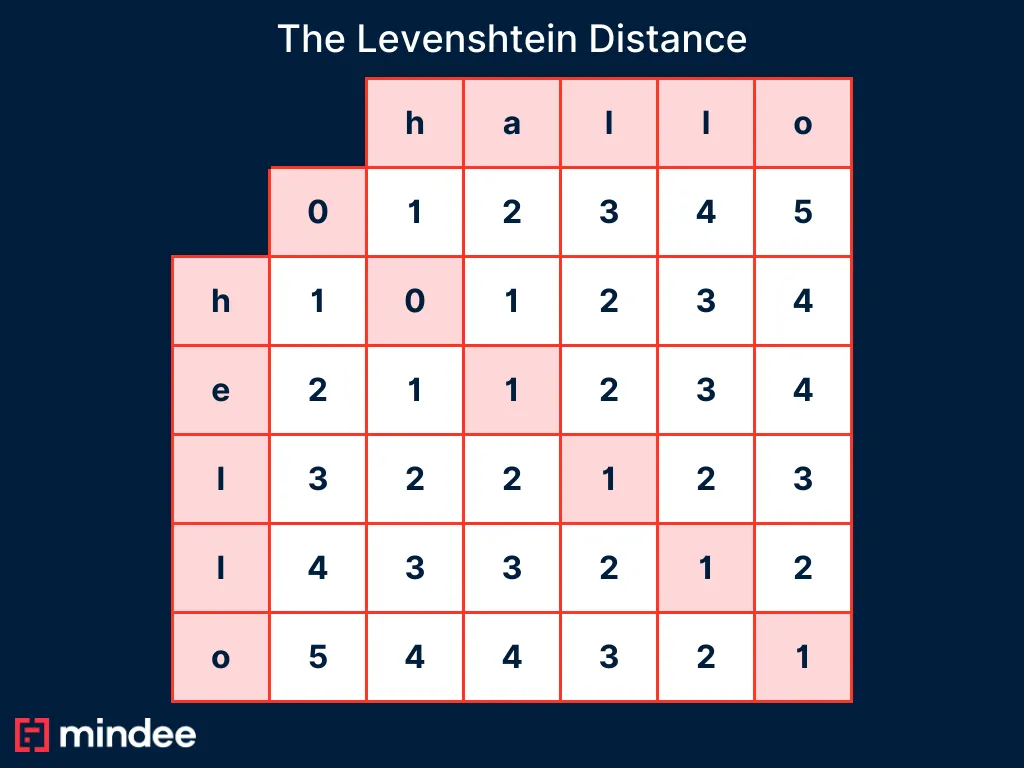
For example, to compute the Levenshtein Distance between "hallo" and "hello":
Substitute "a" with "e" → Cost: 1 operation.
→ The Levenshtein Distance is 1.
When to prioritize the Levenshtein distance?
Levenshtein Distance is especially useful for short text comparisons, handwritten text recognition or to compare similar outputs.
To make Levenshtein Distance more actionable in OCR evaluations, it is often normalized into a percentage by dividing it by the length of the longer string, providing a relative score akin to Character Error Rate (CER).
By combining Levenshtein Distance with CER and Exact Match Rate (EMR), you can create a well-rounded evaluation of OCR performance tailored to your business requirements.
Beyond accuracy: how to evaluate the overall OCR API performance
When it comes to OCR, accuracy is only part of the story. Sure, it’s critical that your OCR gets the text right, but what about the broader picture? Can it handle large volumes of data at speed? Does it perform consistently across diverse document types?
Evaluating an OCR API means looking beyond accuracy to metrics that measure its reliability, efficiency, and real-world performance. That’s where tools like the F1 Score or the automation rate come in, bridging the gap between precision and recall to give you a complete picture!
The F1 score
The F1 Score is a performance metric that represents the harmonic mean of precision and recall.
It is particularly valuable in OCR when you're extracting structured or semi-structured data, like fields in an invoice or items in a receipt.
The F1 Score quantifies how well an OCR system balances these two aspects:
- Precision: The proportion of correctly extracted values out of all values extracted by the OCR system.
- Recall: The proportion of correctly extracted values out of all values that should have been extracted (aka the ground truth).
The F1 Score ensures neither precision nor recall is prioritized disproportionately, giving you a single metric to evaluate overall system effectiveness.
The formula for F1 Score is:
A lower F1 Score indicates better performance, with an ideal value of 1, meaning the OCR system achieves perfect precision and recall.
Suppose an OCR system processes 100 fields. It decides to predict something for 80 fields. Of the 80 fields extracted, 70 are correct.
Then:
- Precision = 70/80 = 0.875
- Recall = 70/100 = 0.7
This F1 Score of 0.778 indicates that the OCR system is fairly effective but has room for improvement.
When to prioritize the F1 Score?
The F1 Score is most useful when evaluating OCR systems for structured data extraction or comparing OCR performance across complex datasets.
By incorporating the F1 Score into your evaluation, you can ensure your OCR solution meets not only accuracy standards but also the broader performance benchmarks required for seamless integration into your workflows.
The automation rate
What is the automation rate?
The Automation Rate is a performance metric that measures how effectively an OCR system enables fully automated workflows without requiring manual intervention.
While accuracy metrics like Exact Match Rate or F1 Score are essential for evaluating OCR precision, the automation rate goes beyond correctness: it tells you how much of your data processing can be done end-to-end without human input.
In practical terms, the automation rate reflects the percentage of documents or fields that are processed entirely correctly by the OCR system, requiring zero manual review or corrections.
This metric is critical for scaling document processing operations and reducing operational costs.
The formula for automation rate is:
For example, if an OCR solution processes 1,000 documents and 850 of them are processed without any manual intervention, the automation rate is:
When to prioritize the automation rate?
The automation rate is most valuable in scenarios where manual intervention adds significant time or cost to the process. It’s also a good metric to ensure high-volume document processing or seamless integration with other systems (like a CRM software).
By focusing on automation rate alongside traditional accuracy metrics, you gain a holistic view of how well an OCR system performs in real-world applications. It’s not just about getting the data right: it’s about how much of the process you can truly automate.
OCR accuracy is the backbone of reliable document automation, but it’s just one piece of the puzzle. Metrics like Exact Match Rate (EMR), Word Error Rate (WER), and Character Error Rate (CER) ensure precision, while indicators like the F1 Score and Automation Rate gauge real-world performance and scalability.
The best OCR solution balances accuracy with automation and adaptability to your specific needs. By combining insights from this guide with your business priorities, you can confidently choose an OCR API that delivers accurate data, reduces manual effort, and scales efficiently.
Explore OCR accuracy in action: Mindee’s Free Benchmark Tool & Use Case
Choosing the right OCR API is a data-driven decision, and tools like Mindee’s free OCR benchmark tool can simplify the process.
This tool lets you evaluate OCR accuracy using real-world datasets and metrics like Exact Match Rate, Word Error Rate, and more. It’s an invaluable resource for comparing providers and finding the best fit for your business needs.
To see these concepts in action, check out the video below, where we break down a real-world case study using Mindee's OCR solution.
You’ll learn how accuracy metrics translate into automation rates and operational efficiency, offering a practical example of how to evaluate OCR performance for your own use case.
Watch the video now to discover how Mindee approaches OCR accuracy and how you can apply these principles to choose the best OCR API for your business!
Ready to transform your workflows? Start with the metrics that matter most to you!
About
.svg)