



Table of Contents
14-day free trial
In this article, we introduce the benefits of using parallelization to run computation sequences using DAG (Directed Acyclic Graph) dependencies. We also discuss the limitations of parallelizing tasks in Python. Lastly, we introduce Tawazi, a Python library that can be used to easily run a DAG computation sequence in parallel.
Context
In the search for faster executions, chip manufacturers are trying to push CPU frequencies as high as possible with each new generation. Since the 70s, manufacturers made this possible by reducing the size of the transistors, thus making the circuits smaller. This has the effects of:
- Reducing resistance of the overall circuit;
- Lowering transmission times and achieving higher bandwidth;
- Fitting more transistors in the same area of silicon – producing more functionality at the same price.
Previously, the number of transistors doubled (on the same chip area) every 18 months following Moore’s law. But this doesn’t hold true anymore due to physical limitations at the quantum level (like tunneling electrons).
These limitations capped the efficiency of the processors at 5 GHz for a long period of time. To maximize silicon performance, manufacturers opted to add extra processor cores (multi-core processor), enabling parallel execution. This enhanced performance, but only for parallelizable applications.
Today, even an average mobile phone CPU has 8 cores. Server CPUs come with 24 or even 48 cores. Hence, it is crucial to take advantage of these parallelization capacities that are otherwise wasted. To get the code to run faster, we need to run parts of it in parallel.
Mindee’s Use Case of DAG execution
Mindee develops APIs that require long calculations. Each API call requires running many heavy computer vision deep learning models, and we process dozens of millions of requests every month. In order to increase the speed of our APIs, we decided to parallelize some parts of the code.
We currently use CPython as our primary programming language at Mindee. CPython is limited by the GIL, which makes it impossible to run Python ByteCode in parallel (CPU Bound). However, we can run Python ByteCode that sleeps and waits in parallel (IO Bound).
For example, a Python program can’t run two “summation (+)” operations in parallel, but it can fetch data from two databases in parallel because at some point, one thread will wait for a response from the server, and the other thread can launch the request and then also wait for the response.
For example, two threads can open two files in parallel and perform two HTTP requests to different servers, or execute code that doesn’t depend on the GIL, like TensorFlow code. For example, this code gets HTML pages of google.com and github.com in parallel:
Modify the script to keep google call only:
Modify script to keep GitHub call only
The total execution time of the program is the maximum execution time of its parallelized tasks, which is arround 1.3seconds.
DAG Parallel execution
Executing parallel tasks might provide faster overall execution. However, not all tasks can be parallelized by simply throwing out more threads. Sometimes the result of a function(s) is needed to execute another function(s) in a RAW (Read After Write) dependency. One can model these dependencies using a DAG.
The execution can be ordered in the following way:
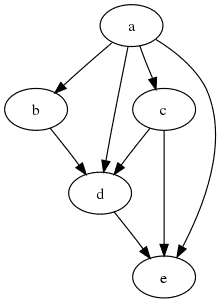
Simple DAG:
- a → b →c →d → e (5-time units)
- a → c →b →d → e (5-time units)
This graph can be executed faster on two threads:
- a→ (b & c) → d → e (4-time units)
We can see that by increasing the number of available threads to two, we can parallelize b and c; so their execution takes up a single time unit. Hence the DAG finishes the execution in 4 seconds instead of 5 seconds. If we ration ⅕ (20%) execution time per API call, we can do 20% more requests with the same number of servers.
DAG Optimizations using priority scheduling
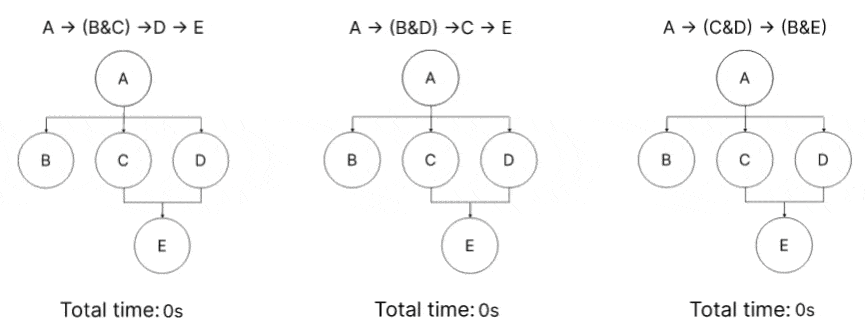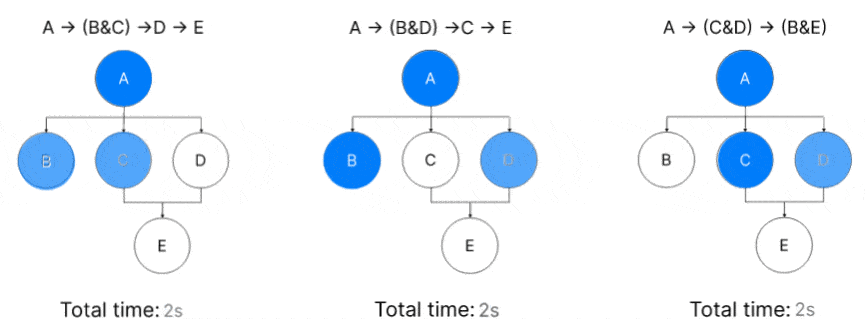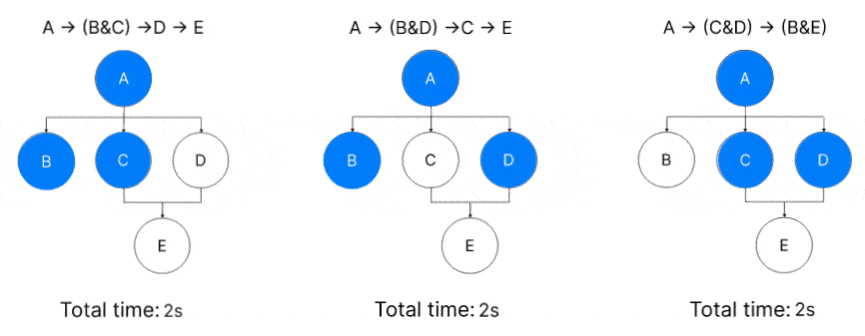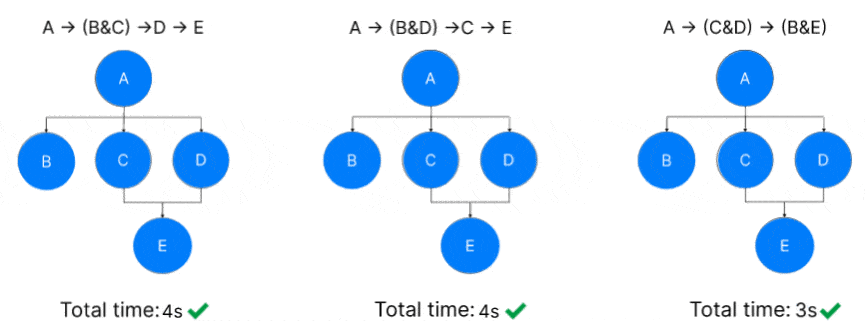
There is a more efficient approach to executing the graph in certain cases: granular optimizations. Take a look at the following DAG:
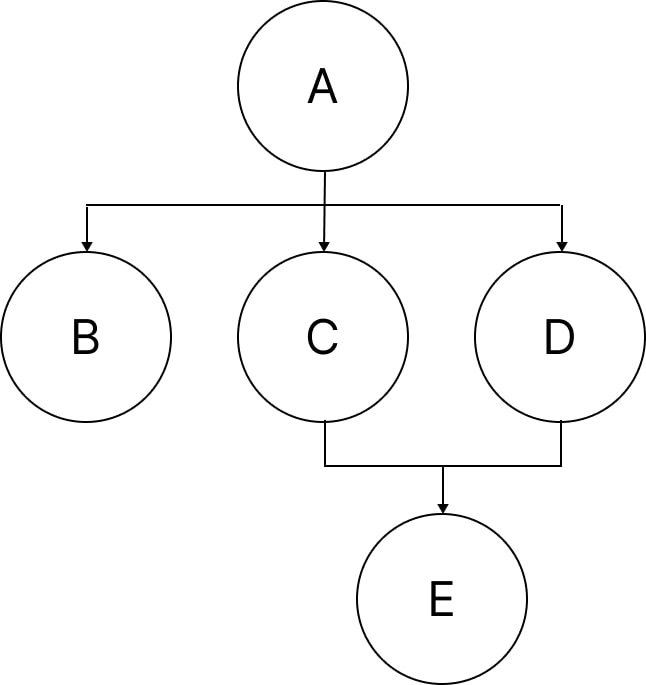
Each Node (A..E) requires 1 second to finish. If we only have two threads available, the possible executions are:
A → (B&C) →D → E ; Total Execution = 4s
A → (B&D) →C → E ; Total Execution = 4s
A → (C&D) → (B&E) ; Total Execution = 3s
We can conclude that by executing C & D before B, a faster global execution can be achieved. Using a priority scheme that places more weight on C & D than on B will accomplish this.
Limitations of the execution of a DAG
The optimization considerations above are mostly true. However, in a real-world scenario, some applications don’t always work as expected: Context Switching problems in parallel applications.
Imagine you have a single-core CPU, and you want to run a program p that takes up 100% of the CPU core. This program takes 1 second to finish. If we run this program 10 times sequentially, it will take 10 seconds to complete. However if we run it in parallel, it will take more!
This is caused by the equitable nature of the OS where it tries to give all the running threads access to the hardware “equally”; but when the hardware is limited, the OS will do context switching between the running threads. Context Switching is expensive, and it might become an important consumer of hardware resources if not managed correctly (for example: by limiting the number of threads that are launched).
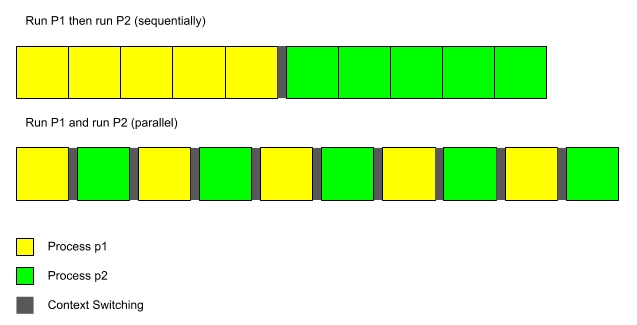
For example, when Tensorflow models run, they can take up all the CPU cores; however, when other computations are also running at the same time, the overall performance goes down!
Faiss is another example of a library that runs extremely fast when no concurrent process is heavily using the CPU, but if there is one, it can become extremely bad: an x1000 degradation in performance was observed. (c.f. Faiss parallelization)

Many other libraries experience the same problem. Even pure Python calculations are faster when they run on a single thread. This is caused by frequent context switches.
In this case, the best choice is to block the execution of all other models. An even better approach is to block the execution of all other CPU-bound tasks and keep the execution of all IO-bound tasks.
What About Parallel Calculations in Python?
As mentioned before, CPU-bound tasks aren’t parallelizable in CPython due to the GIL. Consider the following DAG:
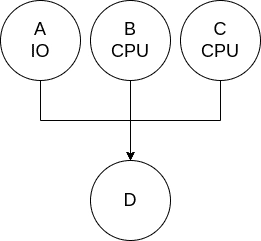
- Each Node (A..D) requires 1 second to finish
- Node A is IO bound (e.g. it fetches data from the internet)
- Nodes B and C do some calculations in Python
If we run the DAG with a maximum concurrency of 3, we can get the most out of the system. However, due to fears of performance degradation (as mentioned in the section above), we decided to disallow B and C to run in parallel. To achieve this, we can limit the maximum number of threads to 2, and make sure that A and B run before C. We will explain later how to do that easily with Tawazi.
Thread-safe DAG execution
Some libraries aren’t Thread Safe. This means that these libraries shouldn’t be used in parallel by different threads because shared data between the parallel executions can get mixed. Parallel usage of the library might produce erroneous results, complete gibberish, or segmentation faults that stop the program completely. Matplotlib, Rtree, and other libraries aren’t thread-safe!
However, these libraries can be used by different threads but not in parallel. This means that the developer must ensure that the library is never used at the same time in these threads.
In order to mitigate the Thread Safety problem, we developed an open source library called tawazi Which, in a nutshell, disables parallelization of non-ThreadSafe code.
It allows the execution of a set of functions (called `ExecNodes`) in parallel while controlling the execution in a granular manner by:
- limiting the number of “Threads” to be used;
- prioritizing the choice of each `ExecNode`;
- and per `ExecNode` choice of parallelization (i.e. An `ExecNode` is allowed to run in parallel with another `ExecNode` or not).
Here is an example of how to use tawazi (version 0.1.2). Here we have the same DAG dependency as What About Parallel Calculations in Python?, in this case, the python_calculation_exec_node is CPU bound, and fetch_distant_data is IO bound:
The total execution time of the calculation parts is equal in both cases. However, when `max_concurrency=3`, we have the illusion that the functions are being executed in parallel, but in reality, they aren’t. The byteCodes get executed in an interleaved manner.
You can play around with the `is_sequential` and the `priority` parameters of the `ExecNode’s` to see how the performance changes.
Conclusion
“The way the processor industry is going is to add more and more cores, but nobody knows how to program those things. I mean, two, yeah; four, not really; eight, forget it.” Steve Jobs, Apple.
Parallel computing is a very complex topic. The internet is full of quotes from programming legends describing the difficulties we face while attempting parallel programming. Tawazi controls it in a granular manner.
The library is still in an advanced state of development so bugs are likely to emerge. However, it has been tested in production and is reliable. We open-sourced it so it can help other developers, and as always, your contributions are highly welcomed.

.svg)


