.svg)


Table of Contents
A RAG system is a type of machine learning model that enhances the output of a language model by integrating external data sources.
Essentially, it retrieves relevant information from a database and uses that information to generate more precise and informed responses.
In this article, we will delve into the intricacies of constructing a Retrieval Augmented Generation (RAG) system. We will clarify the fundamental concepts, architectural components, and implementation strategies involved in building such a system.
Through a comprehensive exploration of the underlying principles and practical considerations, we aim to equip you with the knowledge and tools necessary to develop your own effective RAG system!
What is RAG (Retrieval Augmented Generation)?
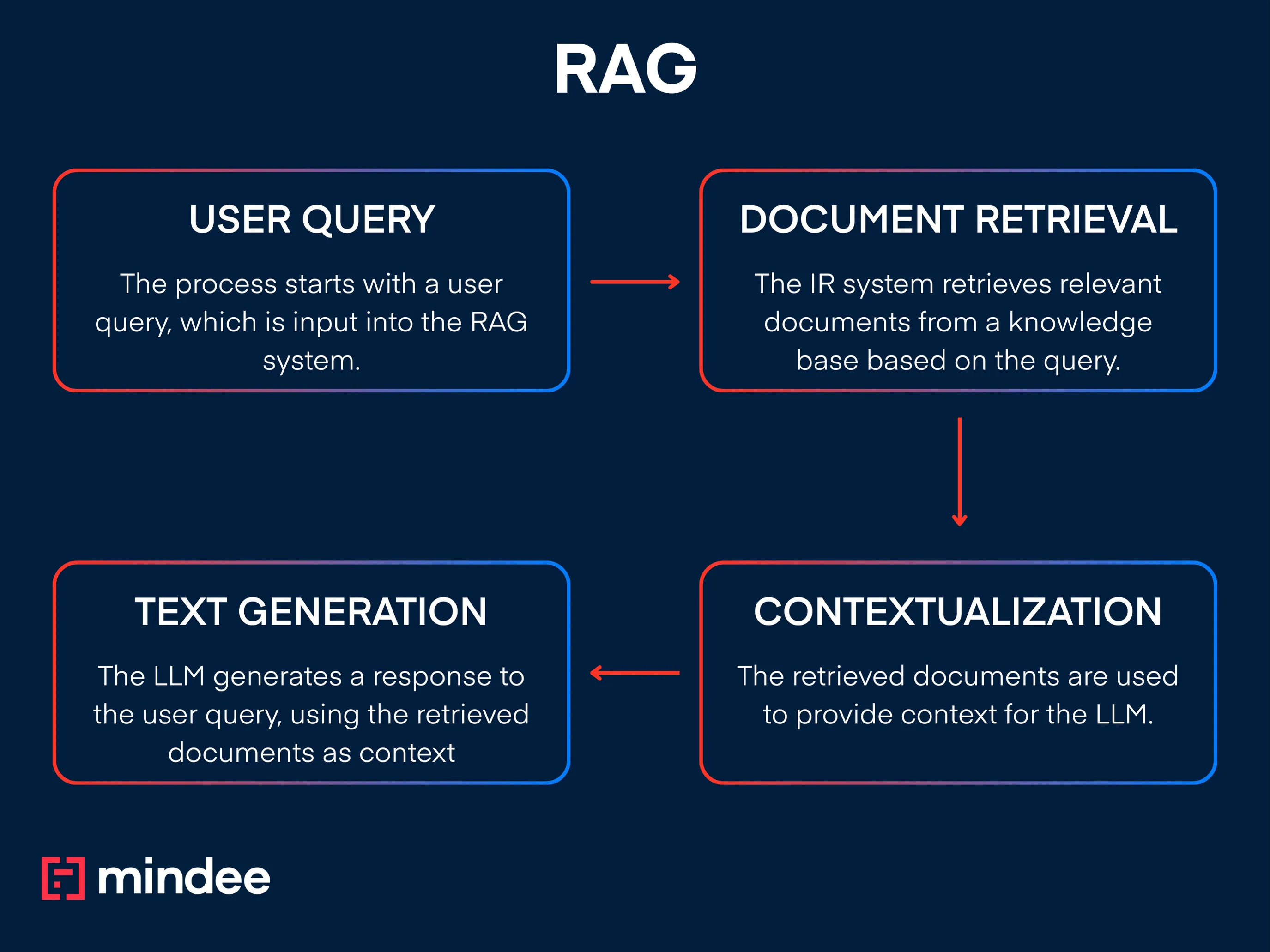
RAG is a framework that combines information retrieval (IR) systems with any Generative Model (but typically large language models better known as LLMs) to improve the quality and accuracy of generated text.
How RAG Works
Applications and Use Cases
RAG systems are particularly valuable in scenarios that demand both accuracy and contextual understanding.
For instance, in customer service, a RAG system can pull up previous customer interactions and product details to offer personalized assistance.
In healthcare, it can extract relevant medical literature to aid in making a precise diagnosis.
The potential applications are vast and span across various industries, making RAG systems a versatile tool for enhancing data-driven interactions.
The Key Components of a RAG System
To build a RAG system, you need to understand its two main components:
- Retriever: This component is responsible for fetching relevant documents or data from a large corpus based on the input query.
- Generator: Once the relevant data is retrieved, the generator uses it to produce a coherent and contextually appropriate response.
Integration of Components
Integrating the retriever and generator is a crucial step in building a RAG system. This integration ensures good communication between the two components, allowing for real-time data retrieval and response generation.
Effective integration involves ensuring compatibility between the data formats used by the retriever and the input requirements of the generator, as well as establishing a smooth workflow for processing queries.
Steps to Build Your Own RAG System
🧰 Step 1: Setting Up the Environment
First, ensure that your development environment is ready. You'll need a programming language that supports machine learning libraries. Python is a popular choice due to its extensive libraries like TensorFlow and PyTorch.
Choosing the Right Tools
Selecting the appropriate tools and libraries is crucial for building an efficient RAG system.
Python's robust ecosystem offers numerous libraries like TensorFlow for deep learning, PyTorch for flexible neural network building, and scikit-learn for basic machine learning operations. These tools provide the foundation upon which the RAG system is built.
Installing Necessary Libraries
Begin by installing the essential Python libraries.
Execute the following command to set up your environment:
pip install torch transformers datasets
These libraries will equip you with the necessary functionalities to build both the retriever and generator components of the RAG system.
Configuring the Development Environment
Ensure your development environment is configured to handle the computational demands of training and running machine learning models.
This may involve setting up virtual environments, ensuring compatibility with your hardware, and optimizing settings for performance.
A well-configured environment will streamline the development process and reduce potential issues.
📦 Step 2: Data Preparation
The success of a RAG system largely depends on the quality and relevance of the data it can retrieve. You need a well-structured dataset that the retriever can access. This dataset should be extensive and relevant to the domain of your application.
Sourcing Quality Data
Begin by identifying and sourcing datasets that align with your application's domain. Resources like Hugging Face Datasets offer a wide array of pre-processed data suitable for various applications.
Ensure that the datasets you choose are comprehensive and up-to-date, as this will directly impact the system's performance.
Structuring and Preprocessing Data
Once sourced, structure and preprocess your data to ensure it is ready for retrieval. This involves cleaning the data, removing duplicates, and organizing it in a format that facilitates efficient searching.
Preprocessing is a crucial step that enhances the accuracy of the retriever by ensuring it operates on high-quality, relevant data.
Ensuring Data Relevance
Continuously assess and update your datasets to maintain their relevance. The dynamic nature of information means that datasets can quickly become outdated.
Regular updates ensure that the RAG system provides accurate and timely responses, enhancing user satisfaction and system reliability.
🧲 Step 3: Building the Retriever
The retriever's job is to find documents that are relevant to the query. You can use techniques like BM25 or more advanced neural retrievers.
For simplicity, let's start with a basic TF-IDF vectorizer.
Implementing a Basic Retriever
Start by implementing a simple TF-IDF vectorizer to understand the retrieval process. This approach uses term frequency-inverse document frequency to rank documents based on their relevance to the input query.
While this example is basic, it provides a solid foundation for understanding retrieval mechanisms.
The following code snippet shows how to import the necessary modules from scikit-learn:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
In addition, you can compute the TF-IDF matrix for a set of documents. For example:
# Example documents
documents = ["Document 1 text", "Document 2 text", "Document 3 text"]
# Create and fit the TF-IDF vectorizer on the documents
vectorizer = TfidfVectorizer().fit_transform(documents)
# Convert the sparse matrix to a dense array
vectors = vectorizer.toarray()
This snippet defines a list of documents, applies the TF-IDF vectorizer to learn the vocabulary and compute the document-term matrix, and finally converts the sparse matrix into a dense array for easier analysis.
Exploring Advanced Retrieval Techniques
Once comfortable with basic retrieval, explore more advanced techniques like BM25 or neural network-based retrievers. These methods offer improved accuracy and efficiency by leveraging deeper insights into the data.
Experiment with different models to find the one that best suits your application needs!
Evaluating Retriever Performance
Regularly evaluate the performance of your retriever using metrics such as precision, recall, and F1-score.
These metrics help identify areas for improvement and ensure the retriever consistently delivers relevant results.
Fine-tuning and iteration are key to optimizing retriever performance!
🧠 Step 4: Developing the Generator
Once the retriever has identified relevant documents, the generator creates the final response.
Setting Up the Generator
Begin by setting up a language model capable of generating coherent responses.
Popular choices include GPT-3 or models available through the Hugging Face Transformers library.
To ensure that the model is appropriately configured to handle data input from the retriever, you can initialize a text-generation pipeline as follows:
from transformers import pipeline
# Configure the text-generation model using a specific model
generator = pipeline("text-generation", model="gpt-3")Crafting Contextual Responses
Leverage the generator to craft responses that are both informative and contextually appropriate. This involves feeding the retrieved documents into the model and specifying parameters like response length and creativity.
Fine-tune these settings to balance informativeness and engagement:
# Combine the relevant documents into a single context string
context = " ".join([documents[i] for i in relevant_docs])
# Generate a response using the configured generator
response = generator(context, max_length=150, num_return_sequences=1)
# Print the generated response
print(response)Enhancing Generative Capabilities
Experiment with different model configurations and parameters to enhance the generator's capabilities.
Explore options such as adjusting temperature settings, using beam search, or incorporating additional training data. These enhancements can significantly improve the quality and relevance of generated responses.
🔗 Step 5: Integrating and Testing the System
With both components in place, integrate them to form your complete RAG system.
Test the system using different queries to ensure it retrieves and generates responses accurately.
Establishing Integration Protocols
Develop protocols for integrating the retriever and generator into a cohesive system. This involves ensuring data compatibility and establishing an efficient workflow for processing queries.
Effective integration is crucial for smooth operation and accurate response generation.
Conducting Comprehensive Testing
Conduct thorough testing to evaluate the system's performance across various scenarios. Use a diverse set of queries to test the system's ability to retrieve relevant data and generate appropriate responses.
Testing helps identify potential issues and areas for improvement.
Iterative Refinement
Refine the system iteratively based on testing feedback. This involves tweaking parameters, addressing any identified issues, and continuously monitoring performance.
Iterative refinement ensures the RAG system remains robust and capable of delivering high-quality responses.
🛠️ Step 6: Fine-tuning and Optimization
To enhance performance, consider fine-tuning both the retriever and the generator on your specific dataset. This involves adjusting the model parameters and training with domain-specific data to improve accuracy and relevance.
Understanding Fine-Tuning Techniques
Familiarize yourself with fine-tuning techniques applicable to both retrieval and generation components. This may involve supervised learning for retrievers and transfer learning for generators.
Understanding these techniques is crucial for optimizing model performance.
Implementing Domain-Specific Training
Engage in domain-specific training to tailor the RAG system to your application's needs. This involves using specialized datasets and training models to recognize and prioritize domain-relevant information.
Domain-specific training enhances the system's ability to deliver precise and relevant responses.
Monitoring and Evaluating Improvements
Continuously monitor the effects of fine-tuning and evaluate improvements using performance metrics. Track changes in accuracy, response quality, and user satisfaction to gauge the effectiveness of your optimization efforts.
Regular evaluation ensures sustained system performance.
🚀 Step 7: Deploying Your RAG System
Once you're satisfied with the performance, deploy your RAG system. This might involve setting up a web server or integrating the system into an existing application.
Preparing for Deployment
Prepare your system for deployment by addressing technical and logistical considerations. This includes ensuring scalability, establishing security protocols, and configuring server environments. Proper preparation minimizes potential deployment issues and ensures a smooth transition.
Choosing Deployment Platforms
Select appropriate platforms for deploying your RAG system. Options range from cloud-based services like AWS or Azure to on-premises solutions. Consider factors like cost, scalability, and ease of integration when choosing a deployment platform.
To sum up, while it might seem complex initially, breaking down the building of a RAG system into manageable steps makes it achievable. By following this guide, you can create a system that enhances the capabilities of traditional language models, providing more informed and context-aware responses.
Remember, the key to a successful RAG system is the quality of your data and the precision of both the retriever and generator components.
With practice and fine-tuning, you can build a robust system that meets your specific application needs!
About
.svg)